Table Of Content
Before we start, I want to note that the recommendation for single-table design applies to a single service. If you have multiple services in your application, each of them should have their own DynamoDB table. You should think of a DynamoDB table similar to an RDBMS instance—everywhere you would have a separate RDBMS instance, you should have a separate DynamoDB table.
Developing with TypeDORM
When you read the data, you must iterate through 1 to N to find the records that you are searching for and then manually combine results. You can easily split the document into multiple documents with the same partition key and separate parts with a different sort key. You can read everything at once if you specify only the portion key or part of it if you also specify the sort key or part of it. So the principle is the same as in the One to Many Relationship Pattern. The sparse index also works if you set the partition key of GSI and not the sort key.
New DynamoDB Table Class – Save Up To 60% in Your DynamoDB Costs Amazon Web Services - AWS Blog
New DynamoDB Table Class – Save Up To 60% in Your DynamoDB Costs Amazon Web Services.
Posted: Wed, 01 Dec 2021 08:00:00 GMT [source]
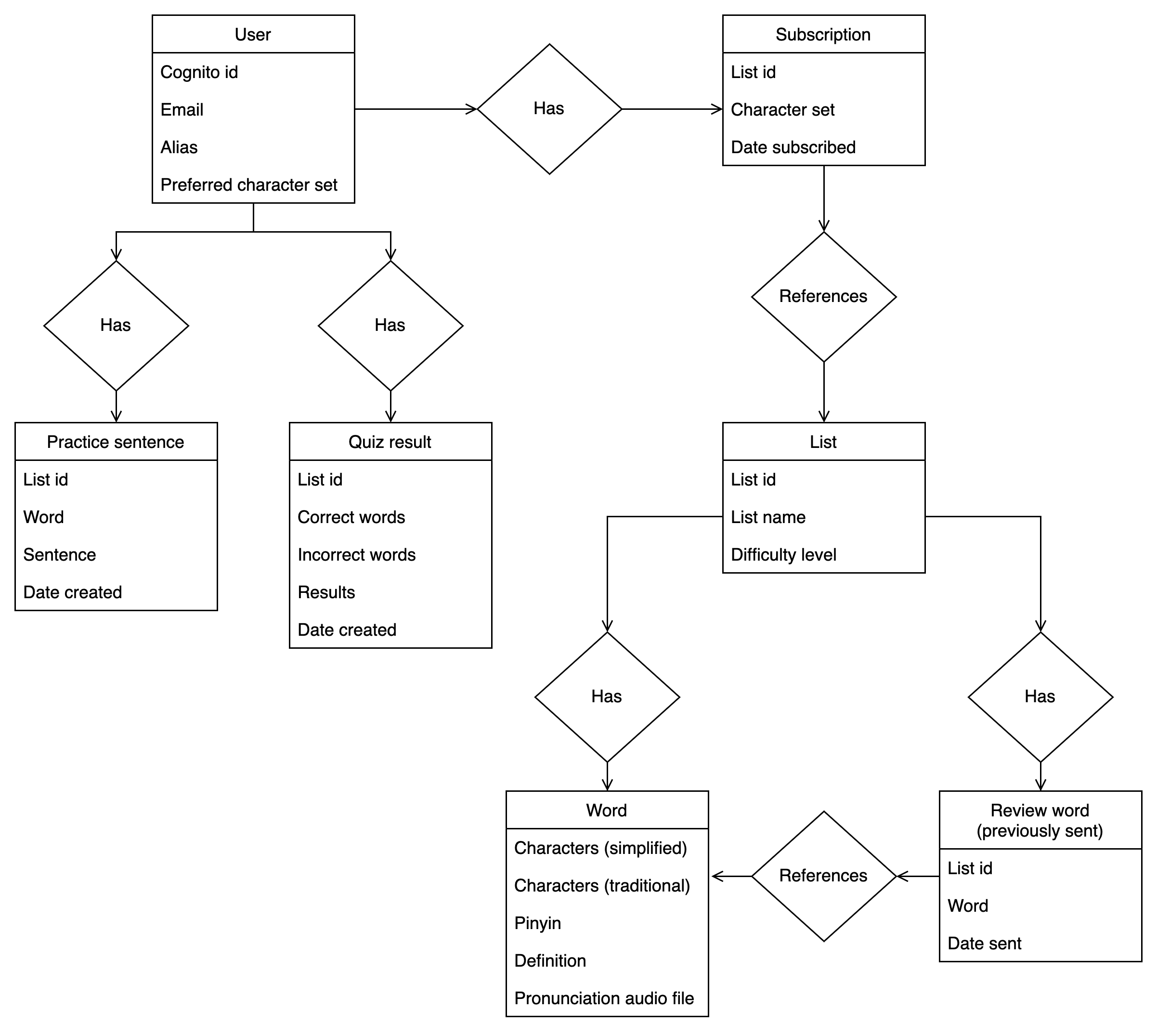
Defining the access patterns
Creating your domain classes that provide the mapping between the application logic and DynamoDB is easier when you combine Project Lombok and the AWS SDK for Java. The following code example demonstrates how to use the Project Lombok annotations and DynamoDBMapper annotations together to create a Java POJO representing the static lift stats domain class. The Project Lombok annotations minimizes the boilerplate code and the DynamoDBMapper annotations provide a mapping between this class and its properties to tables and attributes in DynamoDB. For example the @DynamoDBHashKey and @DynamoDBTable annotations allows DynamoDBMapper to link the getPK() method to the partition key in the table SkiLifts.
Learn About AWS
I'm still a strong proponent of single-table design in DynamoDB in most use cases. And even if you don't think it's right for your situation, I still think you should learn and understand single-table design before opting out of it. Basic NoSQL design principles will help you even if you don't follow the best practices for large-scale design. In this post, we reviewed the concept of single-table design in DynamoDB. First, we went through some history on how NoSQL & DynamoDB evolved and why single-table design is necessary. The web browser makes a single request to our backend server.
Physical Keys
Integrated into our Fastify application, this plugin simplifies the management of areas within the Single Table Design DynamoDB structure. Developers can effortlessly perform CRUD operations on areas, abstracting away the intricacies of database interactions and ensuring a cohesive and efficient development experience. This post showed how to complement the functionality provided by the AWS SDK for Java with the functionality provided by Project Lombok. Such an approach allows for an efficient programming model in Spring Boot–based applications as well as any other Java application. The following table provides some example data in which the items are sorted by the total unique lift riders.
Get a list of races by class ID
You read only the keys of items in the old table with dedicated GSI and then write them back with the migration flag. The stream will take the item, spin an appropriate number of Lambdas, and write restructured data. If you want to keep them in the same table when storing the restructured item, you will trigger the stream again, which is not resource-wise. Make sure you process only unprocessed data, so you do not spin an infinitive loop. However, transactions are not what you are used to in RDBMS databases.
AWS Compute Blog
The fields property could be a different kind of entity inside our table, instead of a map property. We opted to use a map because we will have a small number of fields in each survey. Read on in Part 2 where I cover migrating data to the new DynamoDB table design.
Then we can query all surveys for a specific target and when the date is before the final date of the survey. We still need to filter by the InitialDate but it should be feel results, so it’s okay to simply apply the filter instead of using it in the sort or partition key. For this one, we will use EntityType as the partition key and SK as the sort key. We could list all responses and all surveys pointing to this GSI. Below, I'll walk through designing the data model for the first two access patterns. Dive into the realm of DynamoDB's Single Table Design to demystify the complexities of database management.
New applications that prioritize flexibility

To intuitively understand the use of a GSI, let’s continue with our example. With the DynamoDB Client Plugin, you can effortlessly map and expose various entities within your Fastify application, following the principles of Single Table Design. This streamlined integration empowers developers to focus on building robust features, abstracting away the complexities of DynamoDB interactions.
A key goal in querying DynamoDB data is to retrieve all the required data in a single query request. This is one of the more difficult conceptual ideas when working with NoSQL databases but the single-table design can help simplify data management and maximize query throughput. Finally, define the key structure for the entities to support the defined access patterns. If a table has a partition key and a sort key, it’s possible for items to have the same partition key. Since we partitioned them by their id, we can only fetch one article per query. Sort key identifies the version, except for V0 that only holds the number of the current version.
The physical database primary and secondary keys should have generic names like pk and sk for partition and sort key. For secondary indexes, they should have equally generic names like gs1pk and gs1sk. These physical keys are “overloaded” by multiple entities that use the same physical key attributes for multiple access patterns. This is achieved by using unique prefix labels for key values to differentiate the items. In this way, a single index can be used to query multiple entities in different ways.
There are basic CRUD operations on individual items—PutItem, GetItem, UpdateItem, and DeleteItem. These operations require the full primary key, and you can consider them to be equivalent to a simple lookup in a hash table. While partitioning enables horizontal scaling, we often need to fetch a range of related items in a single request. This is useful in many data applications, such as sorting usernames in alphabetical order or sorting e-commerce orders by the order timestamp. They require scanning large portions of multiple tables in your relational database, comparing different values, and returning a result set.
Further, if you are using DynamoDB On-Demand pricing, you won't save any money by going to a single-table design. DynamoDB closely guards against any operations that won't scale, and there's not a great way to make relational joins scale. Rather than working to make joins scale better, DynamoDB sidesteps the problem by removing the ability to use joins at all. To learn more, read Best practices for storing large items and attributes. The choice here is determined by the traffic patterns in your workload. For applications with predictable traffic with gradual changes, provisioned mode is the better choice and is more cost effective.








No comments:
Post a Comment